MD
https://github.com/DW-Zhou/ES-6.5.4 地址
sojson.com/analyzer ik分词器
Skip to contentPull requestsIssuesMarketplace****Explore
• Watch 2 • Star****20 • Fork****23 • Code • Issues • Pull requests3 • Actions • Projects • Wiki • Security • Insights master ES-6.5.4**/ElasticSearch知识点.mdGo to filedengzhou** ES增加复合查询部分Latest commit 05d54aa on 23 Jul 2020 History 0 contributors1159 lines (949 sloc) 31.6 KBRaw****Blame ElaticSearch 1.索引基本操作 1.1 创建一个索引 #创建一个索引
PUT /person
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
1.2 查看索引信息 #查看索引
GET /person
1.3 删除索引 #删除索引
DELETE /person
1.4 ES中Field可以指定的类型 #String: text:一般用于全文检索。将当前的field进行分词 # keyword: 当前的Field不可被分词 # # # # 1.5 创建索引并指定数据结构 ——以创建小说为例子
PUT /book
{
"settings": {
#备份数
"number_of_replicas": 1,
#分片数
"number_of_shards": 5
},
#指定数据结构
"mappings": {
#指定类型 Type
"novel": {
# 文件存储的Field属性名
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
# 指定当前的Field可以作为查询的条件
"index": true
},
"authoor": {
"type": "keyword"
},
"onsale": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
}
1.6 文档的操作 • 文档在ES服务中的唯一标志,_index, _type, _id 三个内容为组合,来锁定一个文档,操作抑或是修改 1.6.1 新建文档 • 自动生成id PUT /book/novel { "name": "西游记", "authoor": "刘明", "onsale": "2020-12-11" } • 手动指定ID(更推荐) PUT /book/novel/1 { "name": "三国演义", "authoor": "小明", "onsale": "2020-12-11" } 1.6.2 修改文档 • 覆盖式修改 POST /book/novel/1 { "name": "三国演义", "authoor": "小明", "onsale": "2020-12-11" } • doc修改方式(更推荐) POST /book/novel/1/_update { "doc": { "name": "极品家丁" } } #先锁定文档,_update 修改需要的字段即可 1.6.3 删除文档 • 删库跑路 DELETE /book/novel/1 2. java操作ElaticSearch 2.1 Java链接ES 1、创建Maven工程 导入依赖 # 4个依赖 1、1 elasticsearch <!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch --> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.5.4</version> </dependency> 1、2 elasticsearch的高级API <!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.5.4</version> </dependency> 1、3 junit <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> 1、4 lombok <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> <scope>provided</scope> </dependency> 2.1.2 创建测试类,连接ES // 先创建连接,工具类 public class ESClient { public static RestHighLevelClient getClient(){ // 创建HttpHost对象 HttpHost httpHost = new HttpHost("127.0.0.1",9200); // 创建RestClientBuilder RestClientBuilder builder = RestClient.builder(httpHost); // 创建RestHighLevelClien对象 RestHighLevelClient client = new RestHighLevelClient(builder); return client; } } 2.2 java创建索引 import com.dengzhou.utils.ESClient; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.json.JsonXContent; import org.junit.jupiter.api.Test; import java.io.IOException; public class Create_ES_Index { String index = "person"; String type = "man"; @Test public void createIndex() throws IOException { //1、 准备关于索引的settings Settings.Builder settings = Settings.builder() .put("number_of_shards", 3) .put("number_of_replicas", 1); //2、 准备关于索引的结构mappings XContentBuilder mappings = JsonXContent.contentBuilder() .startObject() .startObject("properties") .startObject("name") .field("type","text") .endObject() .startObject("age") .field("type","integer") .endObject() .startObject("birthday") .field("type","date") .field("format","yyyy-MM-dd") .endObject() .endObject() .endObject(); //2 将settings 和 mappings封装成一个request对象 CreateIndexRequest request = new CreateIndexRequest(index) .settings(settings) .mapping(type,mappings); //3 通过client对象去链接es并执行创建索引 RestHighLevelClient client = ESClient.getClient(); CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); //测试 System.out.println("response"+response.toString()); } 2.3 检查索引是否存在,删除索引 //检查索引是否存在 @Test public void exists() throws IOException { //1 准备request对象 GetIndexRequest request = new GetIndexRequest(); request.indices(index); // 2 通过client去检查 RestHighLevelClient client = ESClient.getClient(); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); } 2.4 修改文档 • 添加文档操作 @Test public void createDoc() throws IOException { ObjectMapper mapper = new ObjectMapper(); // 1. 准备json数据 Person person = new Person(1, "张三", 23, new Date()); String json = mapper.writeValueAsString(person); System.out.println(json); // 2. 准备一个request对象(手动指定id创建) IndexRequest indexRequest = new IndexRequest(index,type,person.getId().toString()); indexRequest.source(json, XContentType.JSON); // 3、通过client对象执行添加操作 RestHighLevelClient client = ESClient.getClient(); IndexResponse resp = client.index(indexRequest, RequestOptions.DEFAULT); // 4、 输出返回 System.out.println(resp.getResult().toString()); } • 修改文档 // 修改文档,通过doc方式 @Test public void updateDoc() throws IOException { // 创建map,指定需要修改的内容 Map<String,Object> map = new HashMap<String, Object>(); map.put("name","李四"); String docId = "1"; // 创建一个request对象,封装数据 UpdateRequest updateRequest = new UpdateRequest(index,type,docId); updateRequest.doc(map); // 通过client对象执行 RestHighLevelClient client = ESClient.getClient(); UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT); // 返回输出结果 System.out.println(update.getResult().toString()); } 2.5 删除文档 2.6 java批量操作文档 ◦ 3.ElasticSearch练习 • 索引 : sms-logs-index • 类型:sms-logs-type字段名称备注createDate创建时间StringsendDate发送时间 datelongCode发送长号码 如 16092389287811 stringMobile如 13000000000corpName发送公司名称,需要分词检索smsContent下发短信内容,需要分词检索State短信下发状态 0 成功 1 失败 integerOperatorid运营商编号1移动2联通3电信 integerProvince省份ipAddr下发服务器IP地址replyTotal短信状态报告返回时长 integerFee扣费 integer • 创建实例代码 //先定义索引名和类型名 String index = "sms_logs_index"; String type = "sms_logs_type"; public void create_index() throws IOException { Settings.Builder settings = Settings.builder() .put("number_of_shards", 3) .put("number_of_replicas", 1); XContentBuilder mappings = JsonXContent.contentBuilder() .startObject() .startObject("properties") .startObject("createDate") .field("type", "text") .endObject() .startObject("sendDate") .field("type", "date") .field("format", "yyyy-MM-dd") .endObject() .startObject("longCode") .field("type", "text") .endObject() .startObject("mobile") .field("type", "text") .endObject() .startObject("corpName") .field("type", "text") .field("analyzer", "ik_max_word") .endObject() .startObject("smsContent") .field("type", "text") .field("analyzer", "ik_max_word") .endObject() .startObject("state") .field("type", "integer") .endObject() .startObject("operatorid") .field("type", "integer") .endObject() .startObject("province") .field("type", "text") .endObject() .startObject("ipAddr") .field("type", "text") .endObject() .startObject("replyTotal") .field("type", "integer") .endObject() .startObject("fee") .field("type", "integer") .endObject() .endObject() .endObject(); CreateIndexRequest request = new CreateIndexRequest(index) .settings(settings) .mapping(type,mappings); RestHighLevelClient client = ESClient.getClient(); CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); System.out.println(response.toString()); } ◦ 数据导入部分 PUT /sms_logs_index/sms_logs_type/1 { "corpName": "途虎养车", "createDate": "2020-1-22", "fee": 3, "ipAddr": "10.123.98.0", "longCode": 106900000009, "mobile": "1738989222222", "operatorid": 1, "province": "河北", "relyTotal": 10, "sendDate": "2020-2-22", "smsContext": "【途虎养车】亲爱的灯先生,您的爱车已经购买", "state": 0 } 4. ES的各种查询 4.1 term&terms查询 4.1.1 term查询 • term的查询是代表完全匹配,搜索之前不会对你的关键字进行分词 **
#term匹配查询(完整匹配):
** POST /sms_logs_index/sms_logs_type/_search { "from": 0, #limit from,size "size": 5, "query": { "term": { "province": { "value": "河北" } } } }
##不会对term中所匹配的值进行分词查询 // java代码实现方式 @Test public void testQuery() throws IOException { // 1 创建Request对象 SearchRequest request = new SearchRequest(index); request.types(type); // 2 指定查询条件 SearchSourceBuilder builder = new SearchSourceBuilder(); builder.from(0); builder.size(5); builder.query(QueryBuilders.termQuery("province", "河北")); request.source(builder); // 3 执行查询 RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4 获取到_source中的数据 for (SearchHit hit : response.getHits().getHits()) { Map<String, Object> result = hit.getSourceAsMap(); System.out.println(result); } } • terms是针对一个字段包含多个值得运用 ◦ terms: where province = 河北 or province = ? or province = ? #terms 匹配查询 POST /sms_logs_index/sms_logs_type/_search { "from": 0, "size": 5, "query": { "terms": { "province": [ "河北", "河南" ] } } } // java代码 terms 查询 @Test public void test_terms() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.termsQuery("province","河北","河南")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse resp = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : resp.getHits().getHits()){ System.out.println(hit); } } 4.2 match查询 match查询属于高层查询,它会根据你查询字段类型不一样,采用不同的查询方式 match查询,实际底层就是多个term查询,将多个term查询的结果进行了封装 • 查询的如果是日期或者是数值的话,它会根据你的字符串查询内容转换为日期或者是数值对等 • 如果查询的内容是一个不可被分的内容(keyword),match查询不会对你的查询的关键字进行分词 • 如果查询的内容是一个可被分的内容(text),match则会根据指定的查询内容按照一定的分词规则去分词进行查询 4.2.1 match_all查询 查询全部内容,不指定任何查询条件 POST /sms_logs_index/sms_logs_type/_search { "query": { "match_all": {} } } @Test public void test_match_all() throws IOException { // 创建Request ,放入索引和类型 SearchRequest request = new SearchRequest(index); request.types(type); builder.size(20); //es默认查询结果只展示10条,这里可以指定展示的条数 //指定查询条件 SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.matchAllQuery()); request.source(builder); // 执行查询 RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 获取查询结果,遍历显示 for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit); } } 4.2.2 match查询 根据某个Field POST /sms_logs_index/sms_logs_type/_search { "query": { "match": { "smsContent": "打车" } } } @Test public void test_match_field() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.matchQuery("smsContext","打车")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit); } } 4.2.3 布尔match查询 基于一个Filed匹配的内容,采用and或者or的方式进行连接 # 布尔match查询 POST /sms_logs_index/sms_logs_type/_search { "query": { "match": { "smsContext": { "query": "打车 女士", "operator": "and" #or } } } } @Test public void test_match_boolean() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.matchQuery("smsContext","打车 女士").operator(Operator.AND)); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit); } 4.2.4 multi_match查询 match针对一个field做检索,multi_match针对多个field进行检索,多个key对应一个text POST /sms_logs_index/sms_logs_type/_search { "query": { "multi_match": { "query": "河北", #指定text "fields": ["province","smsContext"] #指定field } } } // java 实现 @Test public void test_multi_match() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); // 查询的文本内容 字段1 字段2 字段3 。。。。。 builder.query(QueryBuilders.multiMatchQuery("河北", "province", "smsContext")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()) { System.out.println(hit); } } 4.3 ES 的其他查询 4.3.1 ID 查询 # id查询 GET /sms_logs_index/sms_logs_type/1 GET /索引名/type类型/id public void test_multi_match() throws IOException { GetRequest request = new GetRequest(index,type,"1"); RestHighLevelClient client = ESClient.getClient(); GetResponse resp = client.get(request, RequestOptions.DEFAULT); System.out.println(resp.getSourceAsMap()); } 4.3.2 ids查询 根据多个id进行查询,类似MySql中的where Id in (id1,id2,id3….) POST /sms_logs_index/sms_logs_type/_search { "query": { "ids": { "values": [1,2,3] #id值 } } } //java代码 @Test public void test_query_ids() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.idsQuery().addIds("1","2","3")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } 4.3.3 prefix查询 前缀查询,可以通过一个关键字去指定一个Field的前缀,从而查询到指定的文档 POST /sms_logs_index/sms_logs_type/_search { "query": { "prefix": { "smsContext": { "value": "河" } } } } #与 match查询的不同在于,prefix类似mysql中的模糊查询。而match的查询类似于严格匹配查询 # 针对不可分割词 @Test public void test_query_prefix() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.prefixQuery("smsContext","河")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } 4.3.4 fuzzy查询 fuzzy查询:模糊查询,我们可以输入一个字符的大概,ES就可以根据输入的内容大概去匹配一下结果,eg.你可以存在一些错别字 #fuzzy查询 #fuzzy查询 POST /sms_logs_index/sms_logs_type/_search { "query": { "fuzzy": { "corpName": { "value": "盒马生鲜", "prefix_length": 2 # 指定前几个字符要严格匹配 } } } } #不稳定,查询字段差太多也可能查不到 // java 实现 @Test public void test_query_fuzzy() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.fuzzyQuery("corpName","盒马生鲜").prefixLength(2)); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } .prefixLength() :指定前几个字符严格匹配 4.3.5 wildcard查询 通配查询,与mysql中的like查询是一样的,可以在查询时,在字符串中指定通配符*和占位符? #wildcard查询 POST /sms_logs_index/sms_logs_type/_search { "query": { "wildcard": { "corpName": { "value": "*车" # 可以使用*和?指定通配符和占位符 } } } } ?代表一个占位符 ??代表两个占位符 // java代码 @Test public void test_query_wildcard() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.wildcardQuery("corpName","*车")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } 4.3.6 range查询 范围查询,只针对数值类型,对某一个Field进行大于或者小于的范围指定 POST /sms_logs_index/sms_logs_type/_search { "query": { "range": { "relyTotal": { "gte": 0, "lte": 3 } } } } 查询范围:[gte,lte] 查询范围:(gt,lt) //java代码 @Test public void test_query_range() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.rangeQuery("fee").lt(5).gt(2)); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } 4.3.7 regexp查询 正则查询,通过你编写的正则表达式去匹配内容 PS: prefix,fuzzy,wildcar和regexp查询效率相对比较低,在对效率要求比较高时,避免去使用 POST /sms_logs_index/sms_logs_type/_search { "query": { "regexp": { "moible": "109[0-8]{7}" # 匹配的正则规则 } } } //java 代码 @Test public void test_query_regexp() throws IOException { SearchRequest request = new SearchRequest(index); request.types(type); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(QueryBuilders.regexpQuery("moible","106[0-9]{8}")); request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request, RequestOptions.DEFAULT); for (SearchHit hit : response.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } } 4.4 深分页Scroll ES对from+size有限制,from和size两者之和不能超过1w 原理: from+size ES查询数据的方式: 1 先将用户指定的关键词进行分词处理 2 将分词去词库中进行检索,得到多个文档的id 3 去各个分片中拉去指定的数据 耗时 4 根据数据的得分进行排序 耗时 5 根据from的值,将查询到的数据舍弃一部分, 6 返回查询结果 Scroll+size 在ES中查询方式 1 先将用户指定的关键词进行分词处理 2 将分词去词库中进行检索,得到多个文档的id 3 将文档的id存放在一个ES的上下文中,ES内存 4 根据你指定给的size的个数去ES中检索指定个数的数据,拿完数据的文档id,会从上下文中移除 5 如果需要下一页的数据,直接去ES的上下文中,找后续内容 6 循环进行4.5操作 缺点,Scroll是从内存中去拿去数据的,不适合做实时的查询,拿到的数据不是最新的 # 执行scroll查询,返回第一页数据,并且将文档id信息存放在ES的上下文中,指定生存时间 POST /sms_logs_index/sms_logs_type/_search?scroll=1m { "query": { "match_all": {} }, "size": 2, "sort": [ { "fee": { "order": "desc" } } ] } #查询下一页的数据 POST /_search/scroll { "scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAACSPFnJjV1pHbENVVGZHMmlQbHVZX1JGdmcAAAAAAAAkkBZyY1daR2xDVVRmRzJpUGx1WV9SRnZnAAAAAAAAJJEWcmNXWkdsQ1VUZkcyaVBsdVlfUkZ2Zw==", "scoll" :"1m" #scorll信息的生存时间 } #删除scroll在ES中上下文的数据 DELETE /_search/scroll/scrill_id //java代码 @Test public void test_query_scroll() throws IOException { // 1 创建SearchRequest SearchRequest request = new SearchRequest(index); request.types(type); // 2 指定scroll信息,生存时间 request.scroll(TimeValue.timeValueMinutes(1L)); // 3 指定查询条件 SearchSourceBuilder builder = new SearchSourceBuilder(); builder.size(2); builder.sort("fee",SortOrder.DESC); builder.query(QueryBuilders.matchAllQuery()); // 4 获取返回结果scrollid ,source request.source(builder); RestHighLevelClient client = ESClient.getClient(); SearchResponse response = client.search(request,RequestOptions.DEFAULT); String scrollId = response.getScrollId(); System.out.println(scrollId); while(true){ // 5 循环创建SearchScrollRequest SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId); // 6 指定scrollid生存时间 scrollRequest.scroll(TimeValue.timeValueMinutes(1L)); // 7 执行查询获取返回结果 SearchResponse scrollResp = client.scroll(scrollRequest, RequestOptions.DEFAULT); // 8.判断是否得到数据,输出 if (scrollResp.getHits().getHits() != null && scrollResp.getHits().getHits().length > 0){ System.out.println("=======下一页的数据========"); for (SearchHit hit : scrollResp.getHits().getHits()){ System.out.println(hit.getSourceAsMap()); } }else{ // 9。判断没有查询到数据-退出循环 System.out.println("没得"); break; } } // 10 创建clearScrollRequest ClearScrollRequest clearScrollRequest = new ClearScrollRequest(); // 11 指定scrollid clearScrollRequest.addScrollId(scrollId); // 12 删除 client.clearScroll(clearScrollRequest,RequestOptions.DEFAULT); } 4.5 delete-by-query 根据term,match等查询方式去删除大量的文档 如果你需要删除的内容,是index下的大部分数据,不建议使用,建议逆向操作,创建新的索引,添加需要保留的数据内容 POST /sms_logs_index/sms_logs_type/_delete_by_query { "query": { "range": { "relyTotal": { "gte": 2, "lte": 3 } } } } ##中间跟你的查询条件,查到什么,删什么t public class test_sms_search2 { String index = "sms_logs_index"; String type = "sms_logs_type"; @Test public void test_query_fuzzy() throws IOException { DeleteByQueryRequest request = new DeleteByQueryRequest(index); request.types(type); request.setQuery(QueryBuilders.rangeQuery("relyTotal").gt("2").lt("3")); RestHighLevelClient client = ESClient.getClient(); BulkByScrollResponse response = client.deleteByQuery(request, RequestOptions.DEFAULT); System.out.println(response.toString()); } } 4.6 复合查询 4.6. 1 bool查询 复合过滤器,可以将多个查询条件以一定的逻辑组合在一起,and or • must : 所有的条件,用must组合在一起,表示AND • must_not:将must_not中的条件,全部不能匹配,表示not的意思,不能匹配该查询条件 • should: 所有条件,用should组合在一起,表示or的意思,文档必须匹配一个或者多个查询条件 • filter: 过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score #查询省份为河北或者河南的 #并且公司名不是河马生鲜的 #并且smsContext中包含软件两个字 POST /sms_logs_index/sms_logs_type/_search { "query": { "bool": { "should": [ { "term": { "province": { "value": "河北" } } }, { "term": { "province": { "value": "河南" } } ], "must_not": [ { "term": { "corpName": { "value": "河马生鲜" } } } ], "must": [ { "match": { "smsContext": "软件" } } ] } } }
Loading complete
boosting查询


这里如果又匹配上了 negative 匹配上后分数会乘以0.5
filter 过滤器查询


ES高亮查询


ES聚合查询
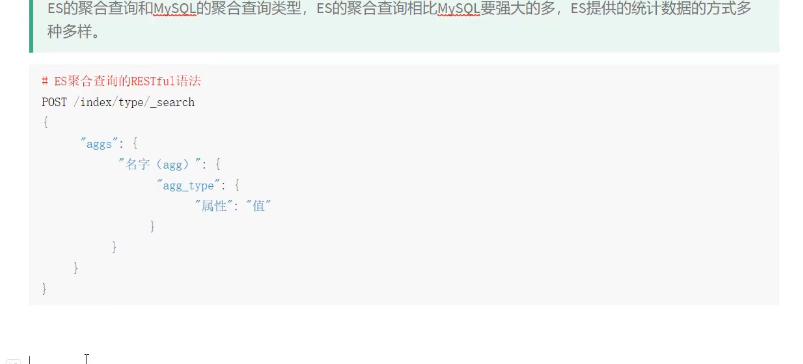
去重计数查询
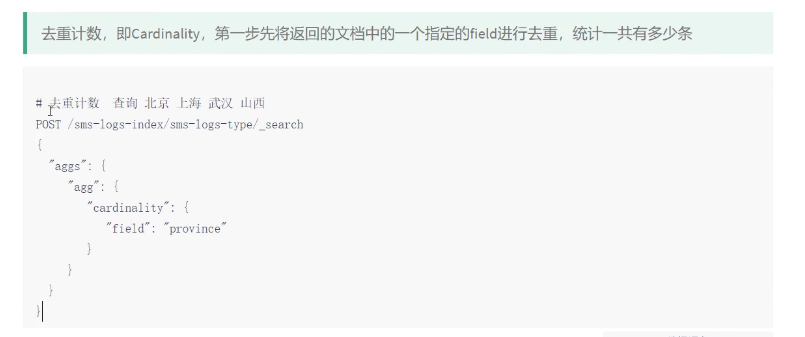
范围统计
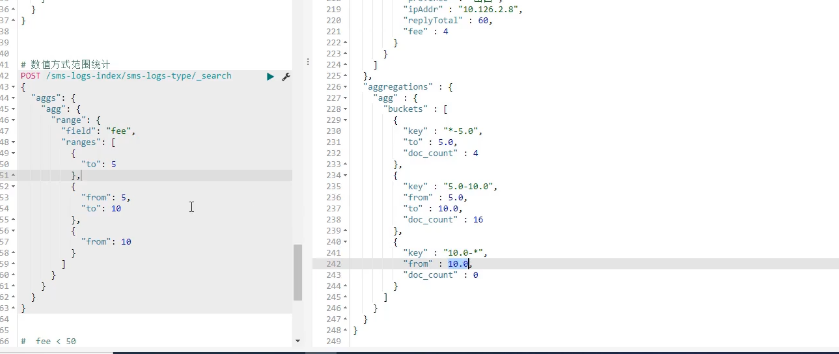
from带等于 to不带等于
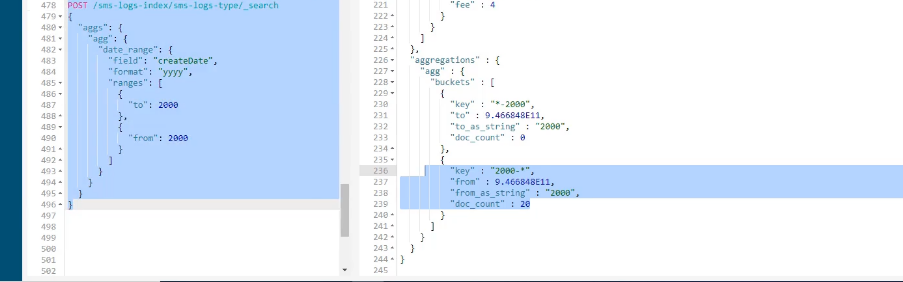
时间范围统计
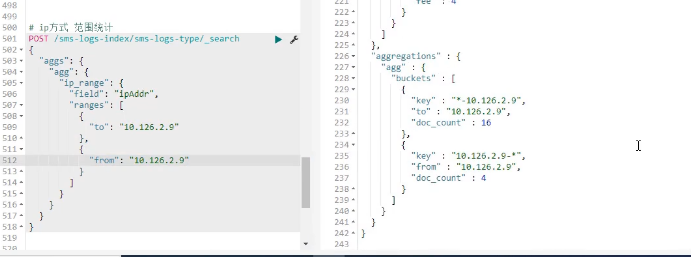
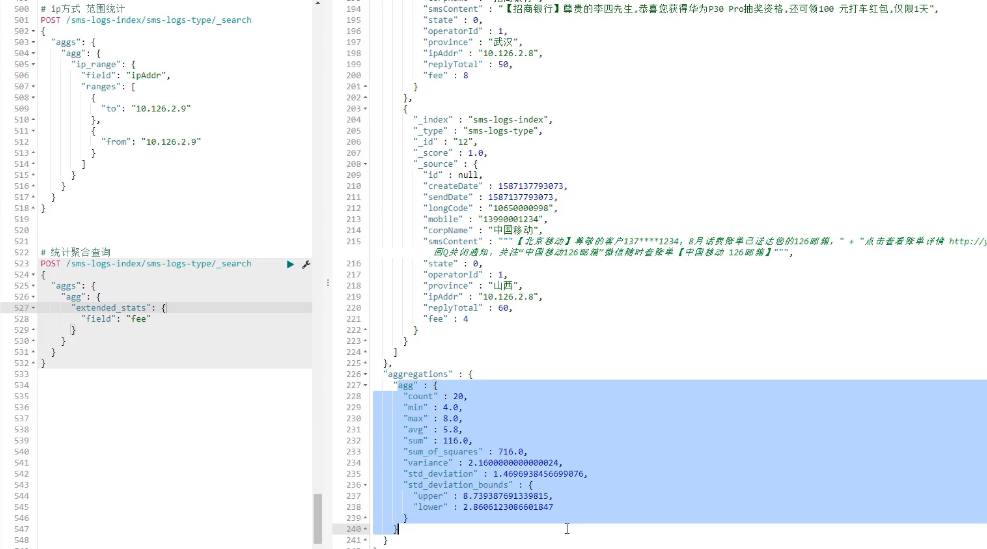
ip方式统计
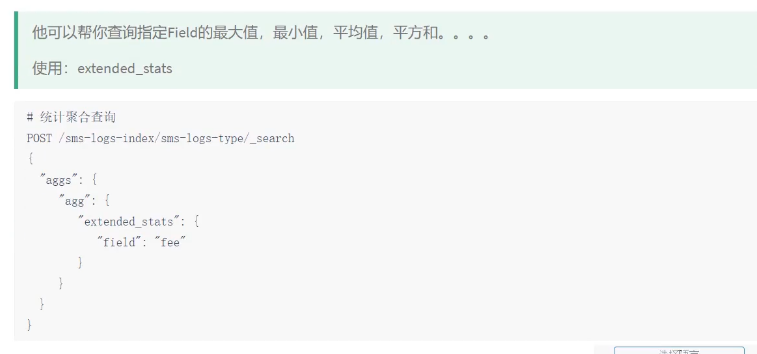
统计聚合查询
$searchParams = [
'index' => $indexArr,
'size' => 0,
'body' => [
'query' => [
'bool' => [
'must' => [
['term' => ['app_id' => $option['app_id']]],
['terms' => ['function_id' => $function->pluck('id')->toArray()]],
]
]
],
'aggs' => [
'func_total' => [
'terms' => [
'size' => 8000,
'field' => 'function_id',
'order' => ['func_users_num.value' => 'desc']
],
'aggs' => [
'sys_customer_num' => ['sum' => ['field' => 'sys_customer_num']], //系统访客数
'func_customer_num' => ['sum' => ['field' => 'func_customer_num']], //功能访客数
'sys_view_num' => ['sum' => ['field' => 'sys_view_num']], //系统访问量
'func_view_num' => ['sum' => ['field' => 'func_view_num']], //功能访问量
'sys_use_num' => ['sum' => ['field' => 'sys_use_num']], //系统使用量
'func_use_num' => ['sum' => ['field' => 'func_use_num']], //功能使用量
'sys_hit_num' => ['sum' => ['field' => 'sys_hit_num']], //系统点击量
'func_hit_num' => ['sum' => ['field' => 'func_hit_num']], //功能点击量
'total_time_on_page' => ['sum' => ['field' => 'total_time_on_page']], //总页面停留时间
'func_users_num' => ['sum' => ['field' => 'func_users_num']], //用户数(计算平均访问深度)
'func_session_num' => ['sum' => ['field' => 'func_session_num']], //会话数
'avg_session_duration' => ['avg' => ['field' => 'avg_session_duration']], //平均会话时长
'total_page_load_time' => ['sum' => ['field' => 'total_page_load_time']], //总网页加载时间
'page_load_sample' => ['sum' => ['field' => 'page_load_sample']], //网页加载样本
]
]
]
]
];
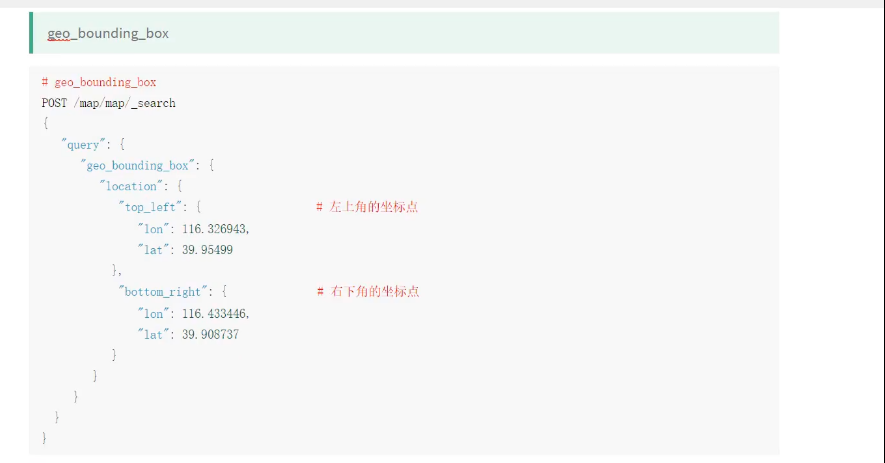
地图经纬度

基于api

https://www.cnblogs.com/yfb918/p/11023581.html#:~:text=elastics,10条数据返回。
分页方案
search_after 的方式
track_total_hits